Collectez les logs de votre cluster Tanzu avec Fluentbit

Les logs sont indispensables au maintien en bonne santé de vos plateformes. Or, dans un environnement conteneurisé, la gestion est radicalement différente. Oubliez l'installation de rsyslog ou le paramétrage de journalctl, avec Kubernetes et plus globalement la conteneurisation applicative, changez vos habitudes dans le traitement de vos logs !
Production des évènements
Une application exécutée dans un conteneur applicatif devrait répondre à un certain nombre de critères dans son développement afin de profiter pleinement des avantages des plateformes Cloud Native. Ces règles sont généralement aux nombres de douze (12 Factor App), mais des variantes plus ou moins nombreuses existent. Regardons de plus près la règle N°11 qui traite spécifiquement de la gestion des évènements.
Il est important que votre application conteneurisée journalise dans ses sorties standards
/dev/stdout ou encore /dev/stderr afin de permettre à votre moteur d'exécution de conteneurs de collecter et de centraliser les évènements.– Using a Sidecar Logging Agent
Pour en apprendre davantage sur l'utilisation des entrées et sorties standards: Linux documentation - I/O Redirection.
Collecte des évènements
Votre moteur d'exécution de conteneurs (containerd, cri-o, ...) va venir collecter les évènements générés par vos applications et les enregistrer au sein d'une arborescence de fichiers, qui se trouve généralement dans /var/log/containers/*.log sur votre machine hôte. Nous aurons alors un fichier par conteneur.

Afin de ne pas saturer le stockage de votre serveur, une politique de rétention et de rotation est définie dans les paramètres de votre moteur d'exécution de conteneurs:
{
"exec-opts": ["native.cgroupdriver=systemd"],
"bridge": "none",
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}Centralisation des évènements avec Fluentbit
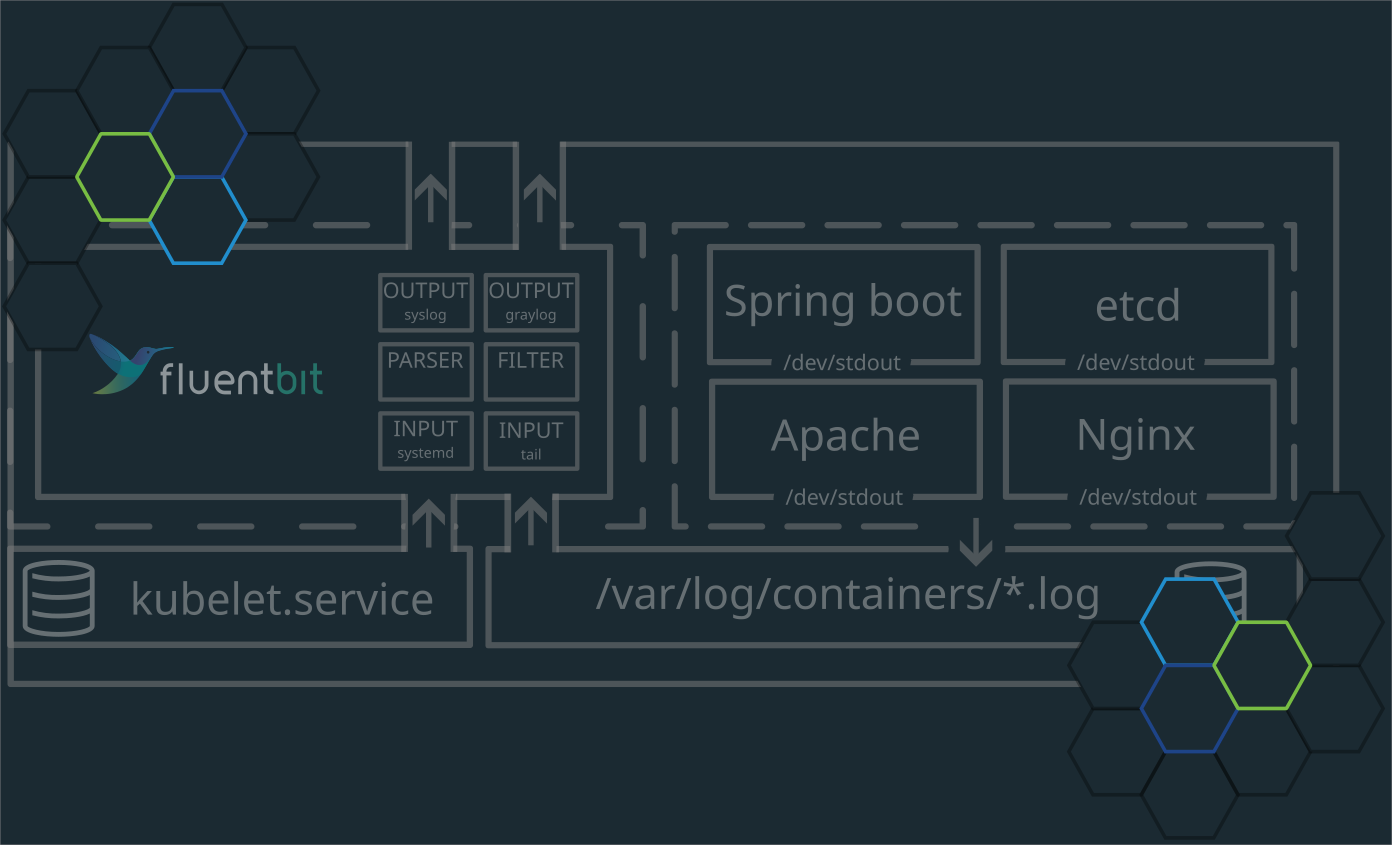
Afin de conserver sur une plus longue durée les évènements relatifs à nos conteneurs, nous devons mettre en oeuvre un composant qui aura pour rôle de venir lire les évènements collectés en local et de les transmettre à un concentrateur externe (SOC, SIEM, Puit de Logs, ...). Ce composant porte le nom d' agent de collecte et de traitement des évènements. Le plus mature à ce jour répertorié auprès de la CNCF dans la catégorie Logging est Fluentbit qui à le statut de Graduated.
Fluentbit se configure par différentes instructions:
| Configuration | Description |
|---|---|
| INPUTS | Définition et paramétrage des connecteurs de récupération d'évènements |
| PARSERS | Les PARSERS sont des composants permettant de découper et d'identifier des éléments dans des données non structurées grâce notamment à des outils comme les REGEXP ou encore les JSON Maps. |
| FILTERS | Les FILTERS vont vous permettre de modifier et de prétraiter vos données. Vous pourrez ainsi venir enrichir vos données au plus proche de la source. |
| OUTPUTS | Les OUTPUT vous permettront de venir définir et paramétrer vos connecteurs de sortie tels que Elasticsearch, Syslog, etc ... |
Deploiement et configuration de Fluentbit sur Tanzu
Pour installer Fluentbit, plusieurs méthodes sont possibles (Helm Chart, Manifest Yaml, Operateurs, etc...). Mais lorsque vous utilisez VMware Tanzu, vous pouvez utiliser le paquet Fluentbit construit et maintenu par les équipes de VMware et ainsi profiter d' une version adaptée à votre environnement. Pour l'installer, deux méthodes, soit via la commande tanzu package, soit par l'interface graphique de Tanzu Mission Control. Nous réaliserons une installation par TMC.
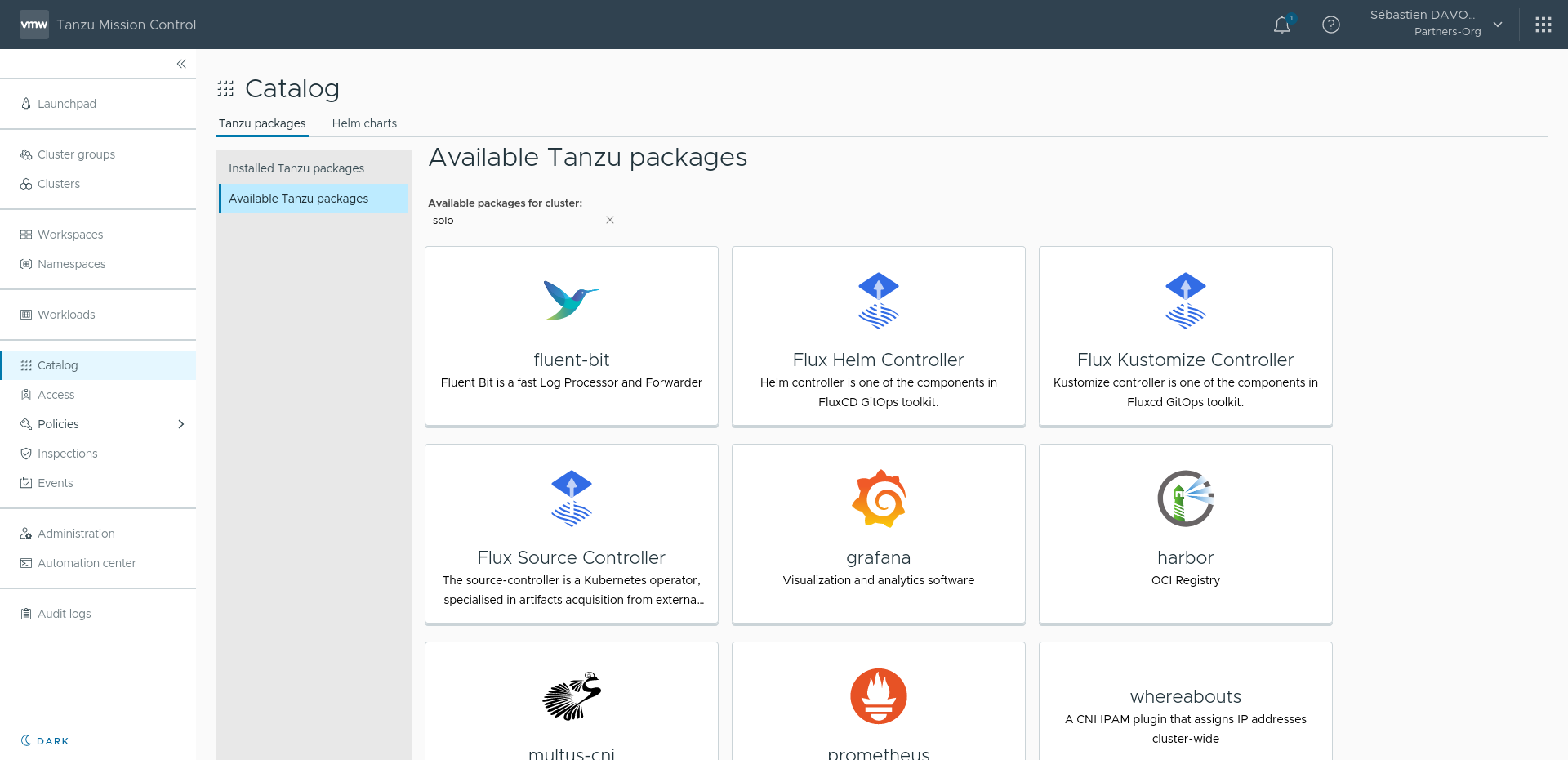
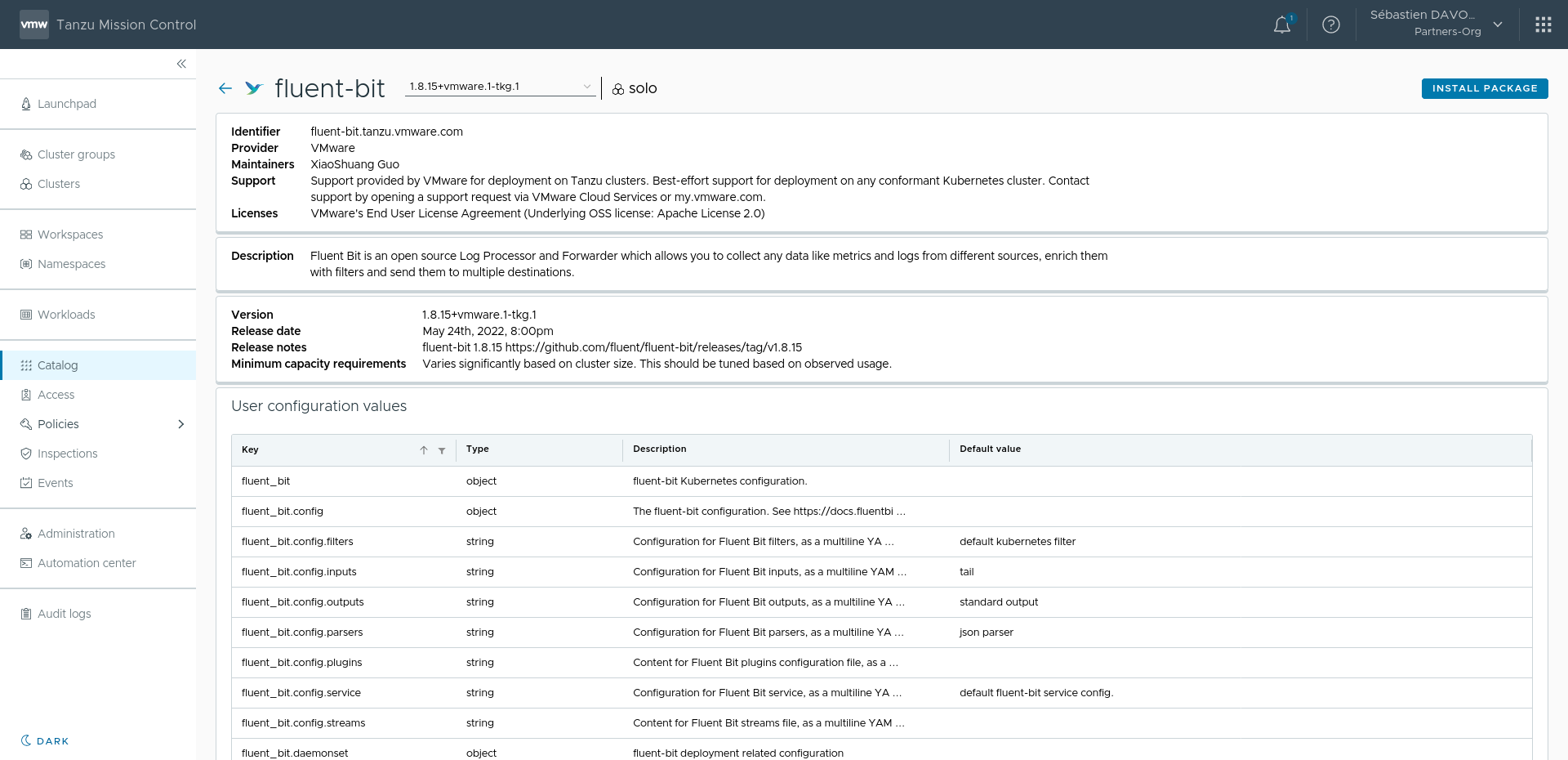
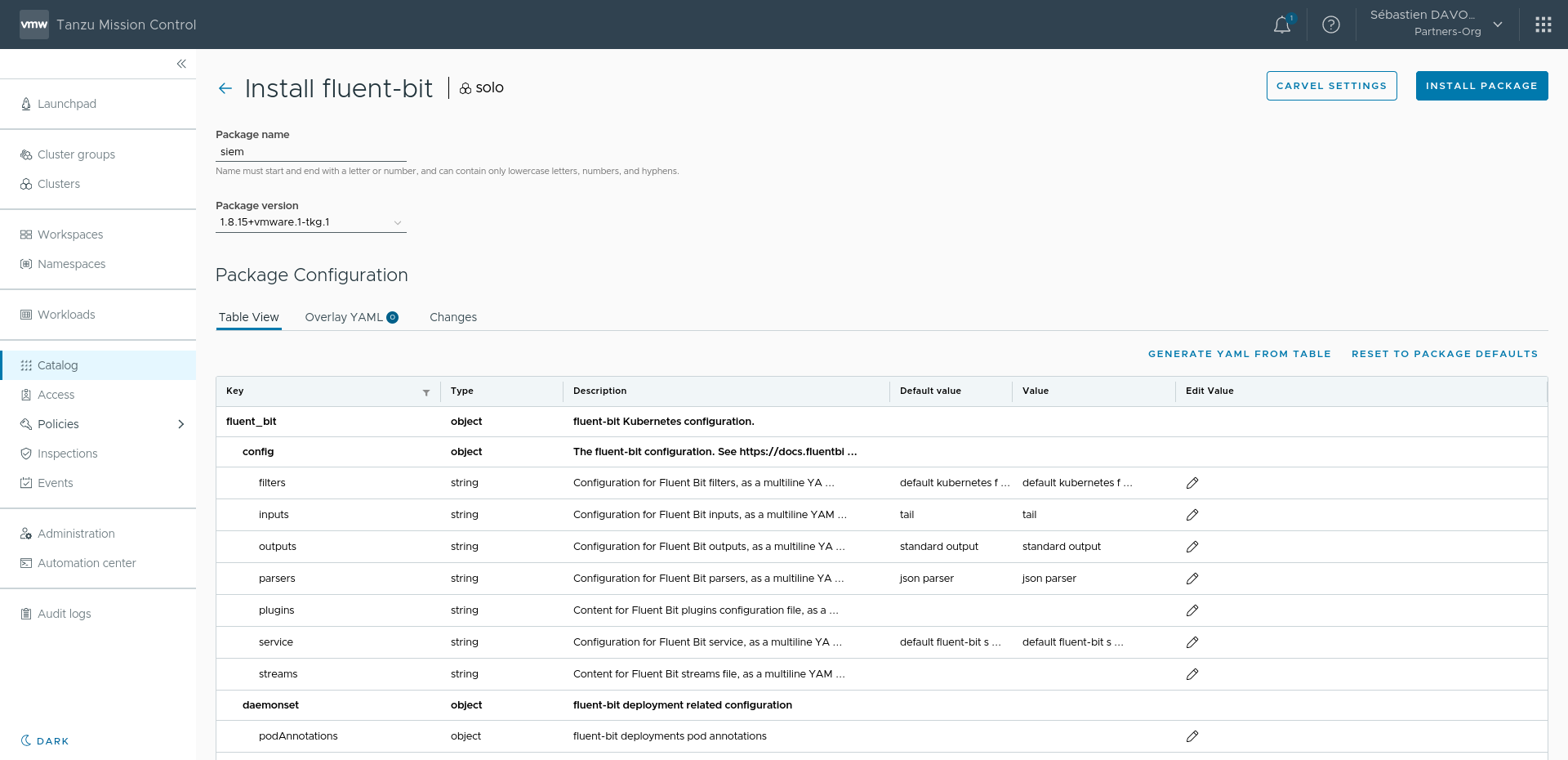
Depuis la vue Catalog de Tanzu Mission Control, nous retrouvons le composant Fluentbit qui est disponible à l'installation sur notre Cluster Tanzu sélectionné un peu plus haut dans la page. Nous sélectionnons ensuite la version de Fluentbit que nous souhaitons installer et nous arrivons enfin sur la dernière page qui nous permet de configurer l'agent. Nous avons pour cela une vue sous forme de tableau dans laquelle chaque ligne peut être éditée grâce au 🖊️ en bout de ligne. Nous retrouvons tous les paramètres de Fluentbit à savoir: INPUT, OUTPUT, FILTERS, PARSERS, ...
Lorsque nous lançons l'installation, nous pouvons vérifier les ressources déployées sur notre cluster Kubernetes:
kubectl get daemonsets.apps,configmaps -n tanzu-system-logging
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/fluent-bit 3 3 3 3 3 <none> 74s
NAME DATA AGE
configmap/fluent-bit-config 7 74s
configmap/kube-root-ca.crt 1 74sUne ressource de type daemonset est déployée afin d'avoir un pod Kubernetes par nœud du Cluster. Cela est nécessaire si vous souhaitez collecter l'ensemble des journaux de vos conteneurs et de vos journaux systemd pour le service Kubelet (qui n'est pas conteneurisé).
Toute la configuration de Fluentbit décrite depuis Tanzu Mission Controle a été définie au sein de votre Cluster Kubernetes dans configmap\fluent-bit-config . Vos changements de configurations Fluentbit peuvent très bien être faits depuis TMC, mais aussi par simple édition de votre configmap kubectl edit configmap/fluent-bit -n tanzu-system-logging . Une synchronisation bidirectionnelle est faite entre TMC et la configmap afin d'éviter tout conflit dans l'édition de la configuration. En fonction de la complexité de la modification, un redémarrage des conteneurs Fluentbit sera lancé.
kubectl rollout restart daemonset -n tanzu-system-logging fluent-bitAller plus loin avec le Mode Debug
Rapidement, vous voudrez venir créer des filtres, découper et enrichir vos évènements, pour cela, rien de mieux que de rajouter un [OUTPUT] nommé stdout dans votre configuration fluentbit.
[OUTPUT]
name stdout
match *Avec ce paramètre, votre agent fluentbit exportera son traitement de données dans son stdout et vous pourrez consulter les évènements grace à la commande:
kubectl logs -n tanzu-system-logging -l app=fluent-bitVous verrez alors votre évènement au format json et connaitrez les clés et les valeurs de vos évènements:
# Evenement JSON en stdout (debug)
]"kube.var.log.containers.mayastor-etcd-0_mayastor_etcd-7d45df799f25fd7a89f02cbeeef4b385e2c9bd63980337bbed129a578ffc99ac.log":[
1675350273.222336594,
{
"stream""=>""stderr",
"logtag""=>""F",
"message""=>""2023-02-02 15:04:33.222087 W | etcdserver: cannot get the version of member 6b985f3365cade67 (Get http://mayastor-etcd-1.mayastor-etcd-headless.mayastor.svc.cluster.local:2380/version: dial tcp 172.20.2.2:2380: connect: connection refused)",
"pod_name""=>""mayastor-etcd-0",
"namespace_name""=>""mayastor",
"pod_id""=>""dd6844d4-1d83-4e96-af72-fbfc5930b479",
"labels""=>"{
"app.kubernetes.io/instance""=>""mayastor",
"app.kubernetes.io/managed-by""=>""Helm",
"app.kubernetes.io/name""=>""etcd",
"controller-revision-hash""=>""mayastor-etcd-f4d8c6bdb",
"helm.sh/chart""=>""etcd-6.2.3",
"statefulset.kubernetes.io/pod-name""=>""mayastor-etcd-0"
},
"host""=>""sap-tkg-workload-cdev-md-2-bc4667d6b-5ht2s",
"container_name""=>""etcd",
"docker_id""=>""7d45df799f25fd7a89f02cbeeef4b385e2c9bd63980337bbed129a578ffc99ac",
"container_hash""=>""docker.io/bitnami/etcd@sha256:e38d9f2facec186c09c33e28455e97156ea45d5c299d348a1b0676784c293d75",
"container_image""=>""docker.io/bitnami/etcd:3.4.15-debian-10-r43"
}
]"``""`"C'est idéal pour vérifier que vos Parsers soient bien utilisés et vous pourrez ainsi réutiliser les clés générées dans vos configurations [OUPUTS].
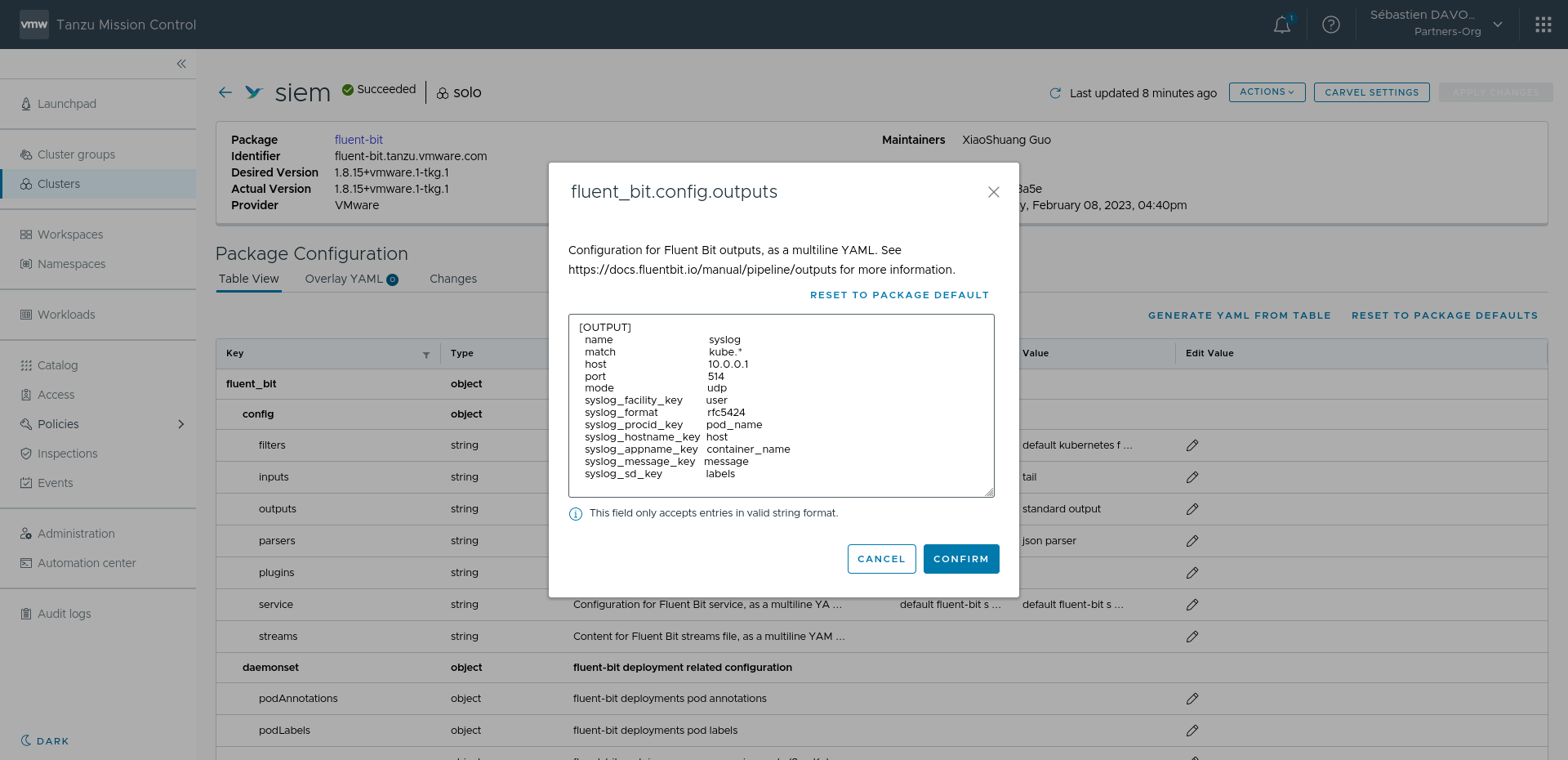
Ci-dessous une configuration vers du Syslog réutilisant les données du [PARSERS] par défaut docker :
[OUTPUT]
name syslog
match kube.*
host 10.0.0.1
port 514
mode udp
syslog_facility_key user
syslog_format rfc5424
syslog_procid_key pod_name
syslog_hostname_key host
syslog_appname_key container_name
syslog_message_key message
syslog_sd_key labelsGrâce au paramétrage syslog dans Fluentbit, nous arrivons à faire le Mapping entre les champs nom du Pod, du Container, ou encore son UUID dans un format connu par la rfc5424. Résultat de l'évènement reçu par le collecteur syslog externe:
# Evenements Syslog
Feb 2 15:19:30 sap-tkg-workload-cdev-md-2-bc4667d6b-5ht2s sync-agent[sync-agent-66d86d96fb-hbfkm] {"apiVersion":"v1","component":"sync-agent","eventType":"LISTED","kind":"ComponentStatus","level":"info","msg":"sent event","name":"scheduler","resourceGroup":"","resourceType":"componentstatuses","resourceVersion":"v1","time":"2023-02-02T15:19:30Z"}
Feb 2 15:19:30 sap-tkg-workload-cdev-md-2-bc4667d6b-5ht2s sync-agent[sync-agent-66d86d96fb-hbfkm] {"apiVersion":"v1","component":"sync-agent","eventType":"LISTED","kind":"ComponentStatus","level":"info","msg":"sent event","name":"etcd-0","resourceGroup":"","resourceType":"componentstatuses","resourceVersion":"v1","time":"2023-02-02T15:19:30Z"}
Feb 2 15:19:30 sap-tkg-workload-cdev-control-plane-q2m6z csi-provisioner[vsphere-csi-controller-774f5fd9b-c9gdt] I0202 15:19:30.980428 1 leaderelection.go:352] lock is held by vsphere-csi-controller-774f5fd9b-hv4qc and has not yet expired